Tracking Whether ChatGPT’s Book Recommendations Work
While refining my AI Literary Cartographer, I found myself returning to a simple but unresolved question:
How will ChatGPT know if one of its book recommendations worked for me?
At first glance, it’s easy to assume that ChatGPT makes suggestions, I follow through, and that’s the end of it. But if this project is about more than just static recommendations, if it's meant to evolve with me, then the absence of memory becomes a real limitation.
Let’s say ChatGPT recommends a book, I read it, and it becomes one of my favourites. Or the opposite happens, I find it flat, misaligned, or entirely forgettable. In both cases, that outcome holds value. But right now, nothing in the system closes that loop. ChatGPT doesn’t remember that it suggested the book, nor does it receive any feedback on whether the suggestion was successful.

That led me to rethink the architecture slightly. The next logical step is to introduce a structured way to log recommendations and outcomes: a simple table that records what was suggested, whether I read it, how I rated it, and whether it earned a place in my personal canon. This feedback would then be fed back into the system the next time I ask for recommendations.
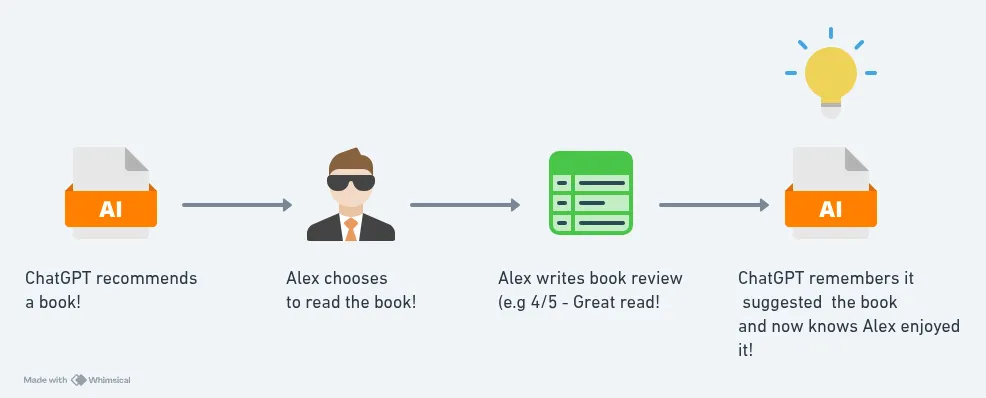
It’s not a complex idea, but it’s a foundational one. It shifts the system from something reactive to something responsive.
Instead of making each request from a blank slate, the AI begins to understand my evolving taste, patterns of disappointment, and what I respond to most strongly, not just in theory, but in practice.
This doesn’t require a radical redesign. It just requires a memory.
What Needs to Be Logged
To create a functioning feedback loop between me and the AI, I’ll be adding a new Google Sheet (or Airtable base) to log the outcome of each recommendation. This creates a long-term memory that allows ChatGPT to evolve based on actual results, not just assumptions.
Here’s a basic structure for the sheet:
🧾 Column Descriptions:
- Timestamp – When the recommendation was made
- Book Title / Author – Self-explanatory
- Recommended by GPT? – Useful for tracking books that were suggested vs books found independently
- Date Read – When the book was completed
- User Rating (1–5) – Standard scale
- All-Time Classic? – Boolean or checkbox
- User Notes – Freeform personal reflections, optional but valuable
- Outcome – Quick summary: “👍 Success”, “👎 Fail”, or “— Pending”
This structure helps distinguish between passive reading and engaged experimentation, giving the agent the ability to learn from experience.