Storing Gmail Newsletters in Google Sheets for AI Training
I wanted to start the AI Literary Cartographer Project by building a daily automation system that extracts content from BookBar newsletters (in Gmail), transforms the messages, and stores the results in Google Sheets. This feature is important as I'll need to capture rich context from all the newsletters I read on a regular basis in order to provide GPT with meaningful background for my personalised book recommendations.
Workflow Overview
The system is built in Pipedream and runs on a daily schedule. Here’s the complete pipeline:
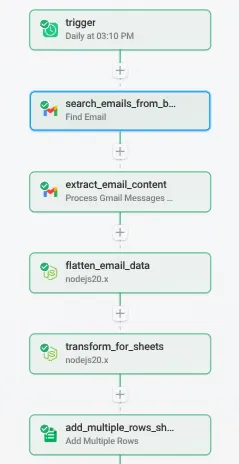
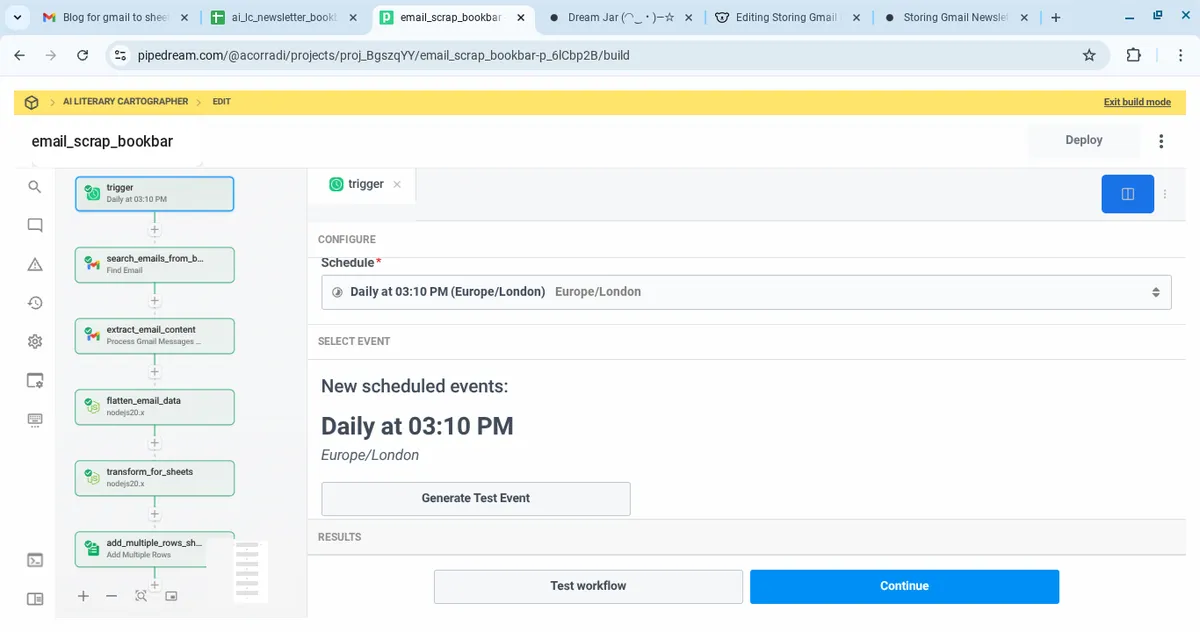
1. Trigger (Daily at 3:10 PM)
User story
As a system, I must automatically initiate the email scraping process daily, so that I can keep the database up to date with the latest BookBar newsletter content.
Steps
- Trigger: Pipedream Cron Scheduler
- Schedule: Daily at 3:10 PM (Europe/London)
No code needed—just configure the time in the UI.
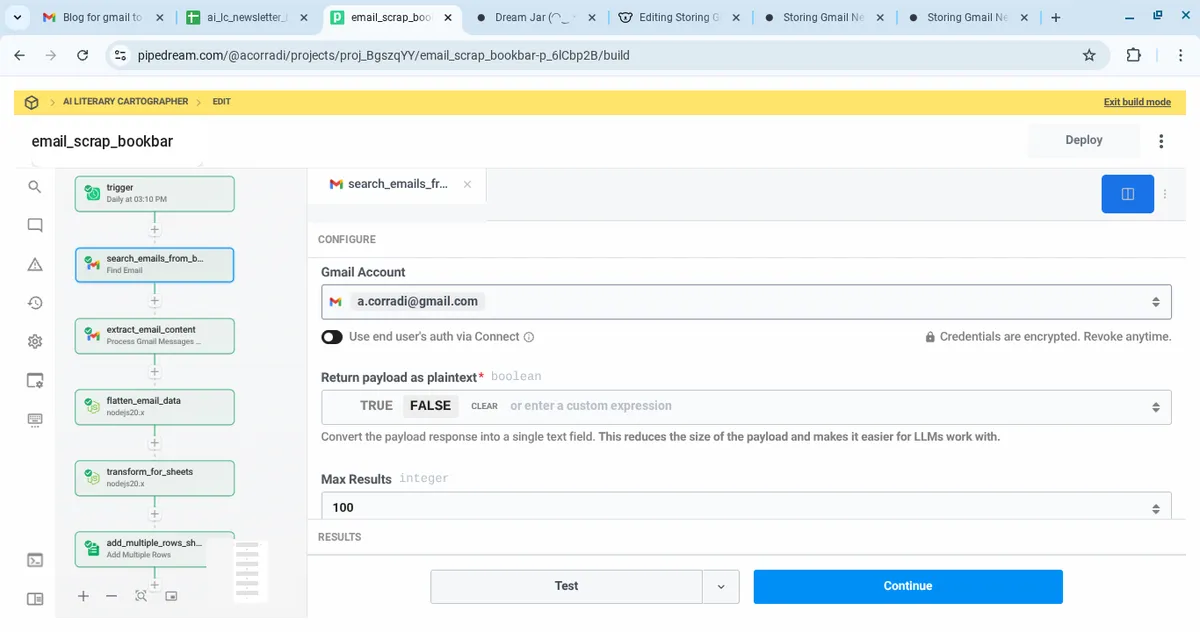
2. Search Emails from BookBar
User story
As a system, I must search for emails from BookBar in Gmail, so that I can identify which messages need to be processed.
Steps
- App: Gmail (Search Email)
- Query:
from:bookbar - Limit: 100
- Output: Email message objects
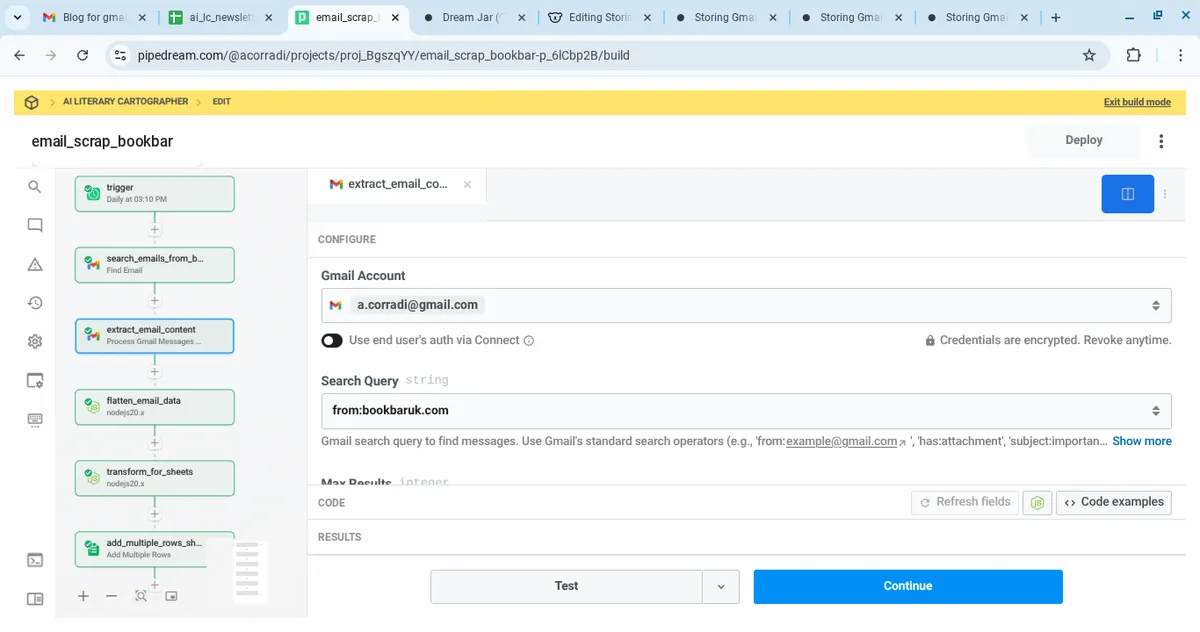
3. Extract Email Content
User story
As a system, I must extract full MIME content from each email, so that I can access the subject, plain text, HTML, and timestamp.
Steps
- App: Gmail (Process Gmail Messages)
- Input:
{{steps.search_emails_from_bookbar.$return_value}} - Output: MIME content per message
Code
import { axios } from "@pipedream/platform"
import gmail from "@pipedream/gmail"
export default defineComponent({
name: "Process Gmail Messages Array",
description: "Process array of Gmail messages from search results and extract raw MIME data and content from each email including nested MIME parts, attachments, HTML content, plain text, headers, and metadata with proper error handling",
type: "action",
props: {
gmail,
q: {
propDefinition: [
gmail,
"q",
],
description: "Gmail search query to find messages. Use Gmail's standard search operators (e.g., 'from:example@gmail.com', 'has:attachment', 'subject:important')",
},
maxResults: {
type: "integer",
label: "Max Results",
description: "Maximum number of messages to process (default: 10, max: 500)",
optional: true,
default: 10,
min: 1,
max: 500,
},
includeAttachmentData: {
type: "boolean",
label: "Include Attachment Data",
description: "Whether to download and include the actual attachment data (base64 encoded). Warning: This may significantly increase processing time and memory usage.",
optional: true,
default: false,
},
},
methods: {
async processMimeParts(parts, messageId) {
if (!parts || !Array.isArray(parts)) return [];
const processedParts = [];
for (const part of parts) {
const processedPart = {
partId: part.partId,
mimeType: part.mimeType,
filename: part.filename || null,
headers: part.headers || [],
body: {
size: part.body?.size || 0,
attachmentId: part.body?.attachmentId || null,
},
};
if (part.body?.data) {
try {
processedPart.body.data = Buffer.from(part.body.data, 'base64').toString('utf-8');
} catch (error) {
processedPart.body.dataError = `Failed to decode body data: ${error.message}`;
}
}
if (part.body?.attachmentId && this.includeAttachmentData) {
try {
const attachment = await this.gmail.getAttachment({
messageId,
attachmentId: part.body.attachmentId,
});
processedPart.body.attachmentData = attachment.data;
processedPart.body.attachmentSize = attachment.size;
} catch (error) {
processedPart.body.attachmentError = `Failed to fetch attachment: ${error.message}`;
}
}
if (part.parts && part.parts.length > 0) {
processedPart.parts = await this.processMimeParts(part.parts, messageId);
}
processedParts.push(processedPart);
}
return processedParts;
},
extractContentByType(parts, mimeType) {
if (!parts) return [];
const content = [];
for (const part of parts) {
if (part.mimeType === mimeType && part.body?.data) {
try {
content.push({
partId: part.partId,
content: Buffer.from(part.body.data, 'base64').toString('utf-8'),
size: part.body.size,
});
} catch (error) {
content.push({
partId: part.partId,
error: `Failed to decode ${mimeType} content: ${error.message}`,
});
}
}
if (part.parts) {
content.push(...this.extractContentByType(part.parts, mimeType));
}
}
return content;
},
extractAttachments(parts) {
if (!parts) return [];
const attachments = [];
for (const part of parts) {
if (part.filename && part.body?.attachmentId) {
attachments.push({
partId: part.partId,
filename: part.filename,
mimeType: part.mimeType,
attachmentId: part.body.attachmentId,
size: part.body.size,
});
}
if (part.parts) {
attachments.push(...this.extractAttachments(part.parts));
}
}
return attachments;
},
extractHeaders(message) {
const headers = {};
const headersList = message.payload?.headers || [];
for (const header of headersList) {
const key = header.name.toLowerCase();
headers[key] = header.value;
}
return headers;
},
},
async run({ $ }) {
try {
$.export("$summary", "Searching for Gmail messages...");
const searchResults = await this.gmail.listMessages({
q: this.q,
maxResults: this.maxResults,
});
if (!searchResults.messages || searchResults.messages.length === 0) {
$.export("$summary", "No messages found matching the search criteria");
return {
totalMessages: 0,
messages: [],
};
}
$.export("$summary", `Processing ${searchResults.messages.length} messages...`);
const processedMessages = [];
let successCount = 0;
let errorCount = 0;
for (let i = 0; i < searchResults.messages.length; i++) {
const messageRef = searchResults.messages[i];
try {
const [fullMessage, rawMessage] = await Promise.all([
this.gmail.getMessage({ id: messageRef.id }),
this.gmail.getMessage({ id: messageRef.id, format: 'raw' }).catch(() => null),
]);
const headers = this.extractHeaders(fullMessage);
const mimeParts = await this.processMimeParts(fullMessage.payload.parts, messageRef.id);
const textContentRaw = this.extractContentByType(fullMessage.payload.parts, 'text/plain');
const htmlContentRaw = this.extractContentByType(fullMessage.payload.parts, 'text/html');
const textContent = textContentRaw.map(p => p.content).join('\n') || '';
const htmlContent = htmlContentRaw.map(p => p.content).join('\n') || '';
const attachments = this.extractAttachments(fullMessage.payload.parts);
const processedMessage = {
id: fullMessage.id,
threadId: fullMessage.threadId,
labelIds: fullMessage.labelIds || [],
snippet: fullMessage.snippet,
historyId: fullMessage.historyId,
internalDate: fullMessage.internalDate,
sizeEstimate: fullMessage.sizeEstimate,
headers,
subject: headers.subject || '',
from: headers.from || '',
to: headers.to || '',
date: headers.date || '',
rawMimeData: rawMessage?.raw || null,
payload: {
partId: fullMessage.payload.partId,
mimeType: fullMessage.payload.mimeType,
filename: fullMessage.payload.filename,
headers: fullMessage.payload.headers,
parts: mimeParts,
},
content: {
html: htmlContent,
text: textContent,
},
attachments,
processedAt: new Date().toISOString(),
processingIndex: i + 1,
};
processedMessages.push(processedMessage);
successCount++;
} catch (error) {
errorCount++;
processedMessages.push({
id: messageRef.id,
error: error.message,
errorType: error.constructor.name,
processedAt: new Date().toISOString(),
processingIndex: i + 1,
});
}
}
const summary = `Successfully processed ${successCount} messages, ${errorCount} errors`;
$.export("$summary", summary);
return {
searchQuery: this.q,
totalMessages: searchResults.messages.length,
successCount,
errorCount,
includeAttachmentData: this.includeAttachmentData,
processedAt: new Date().toISOString(),
messages: processedMessages,
};
} catch (error) {
throw new Error(`Failed to process Gmail messages: ${error.message}`);
}
},
});
4. Flatten Email Data (Node.js)
User story
As a system, I must flatten the nested structure of Gmail MIME messages, so that I can work with a clean array of objects.
Steps
- Language: Node.js 20.x
- Step Name:
flatten_email_data - Input:
{{steps.extract_email_content.$return_value.messages}}
Code
export default defineComponent({
props: {
emailMessages: {
type: "any",
label: "Email Messages",
},
},
async run({ $ }) {
return this.emailMessages.map(msg => ({
timestamp: msg.internalDate,
subject: msg.payload.headers.find(h => h.name === "Subject")?.value || "(No Subject)",
text: Buffer.from(msg.payload.parts?.[0]?.body?.data || "", "base64").toString("utf-8"),
html: Buffer.from(msg.payload.parts?.[1]?.body?.data || "", "base64").toString("utf-8")
}));
}
});
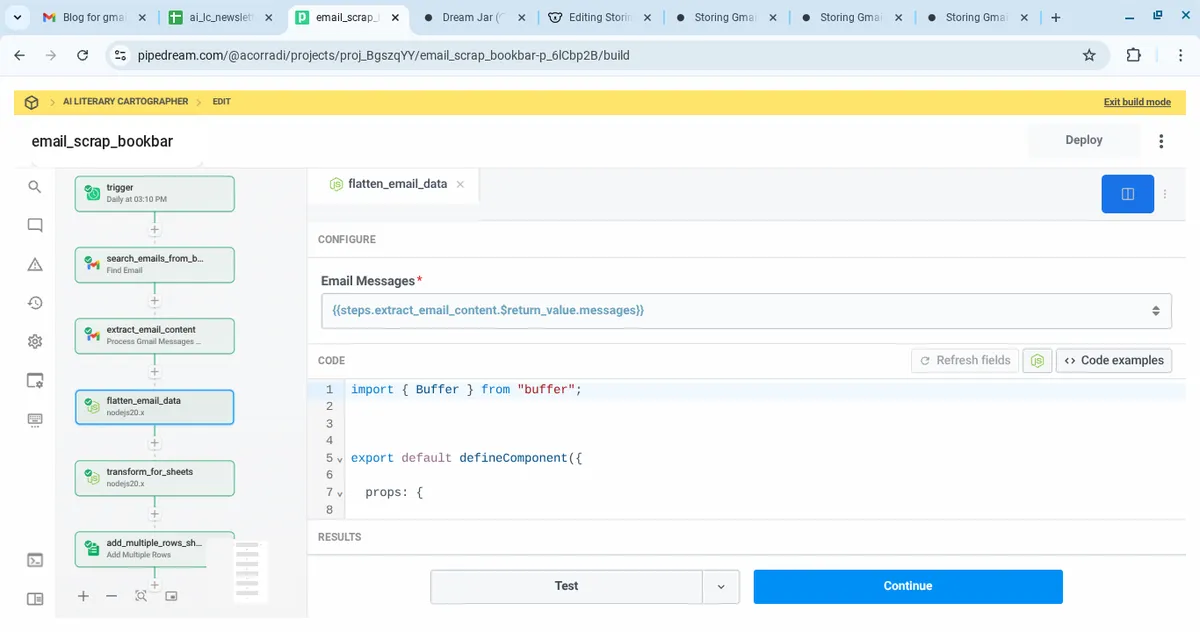
5. Transform for Sheets (Node.js)
User story
As a system, I must transform the email objects into row arrays, so that I can write them to Google Sheets.
Steps
- Language: Node.js 20.x
- Step Name:
transform_for_sheets - Input:
{{steps.flatten_email_data.$return_value}}
Code
export default defineComponent({
props: {
flattenedEmails: {
type: "any",
label: "Flattened Email Data"
}
},
async run({ $ }) {
return this.flattenedEmails.map(email => [
email.timestamp,
email.subject,
email.text,
email.html
]);
}
});
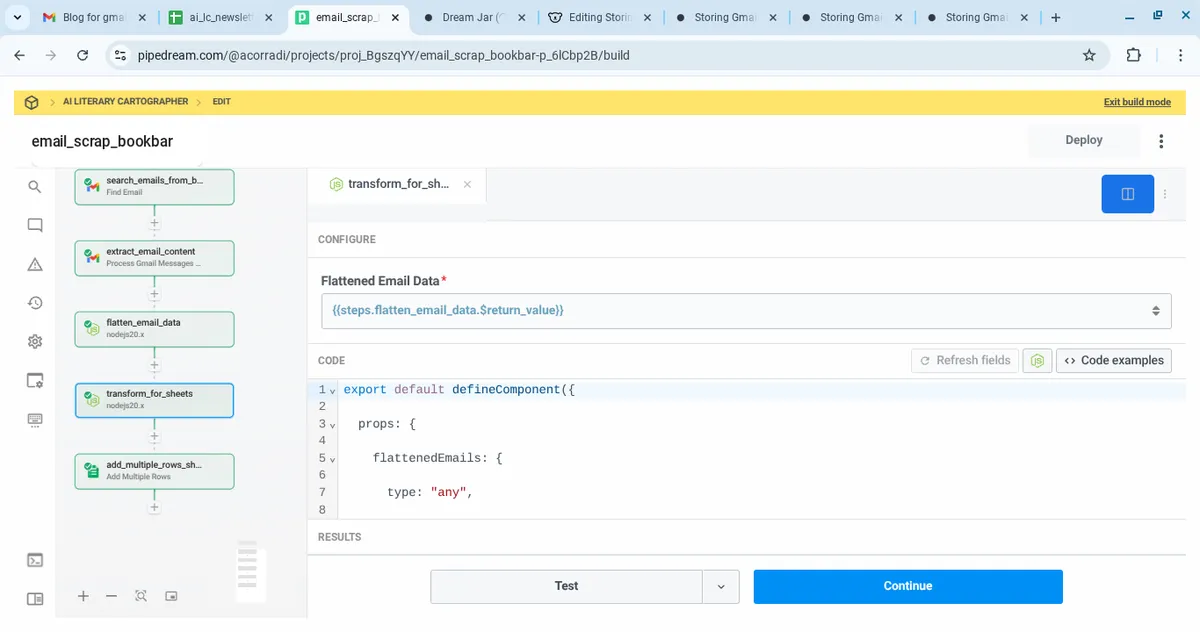
6. Add Rows to Google Sheet
User story
As a system, I must store each email as a new row in Google Sheets, so that the data can be used later by the AI Literary Cartographer.
Steps
- App: Google Sheets
- Action: Add Multiple Rows
- Target:
ai_lc_newsletter_bookbar - Input:
{{steps.transform_for_sheets.$return_value}}
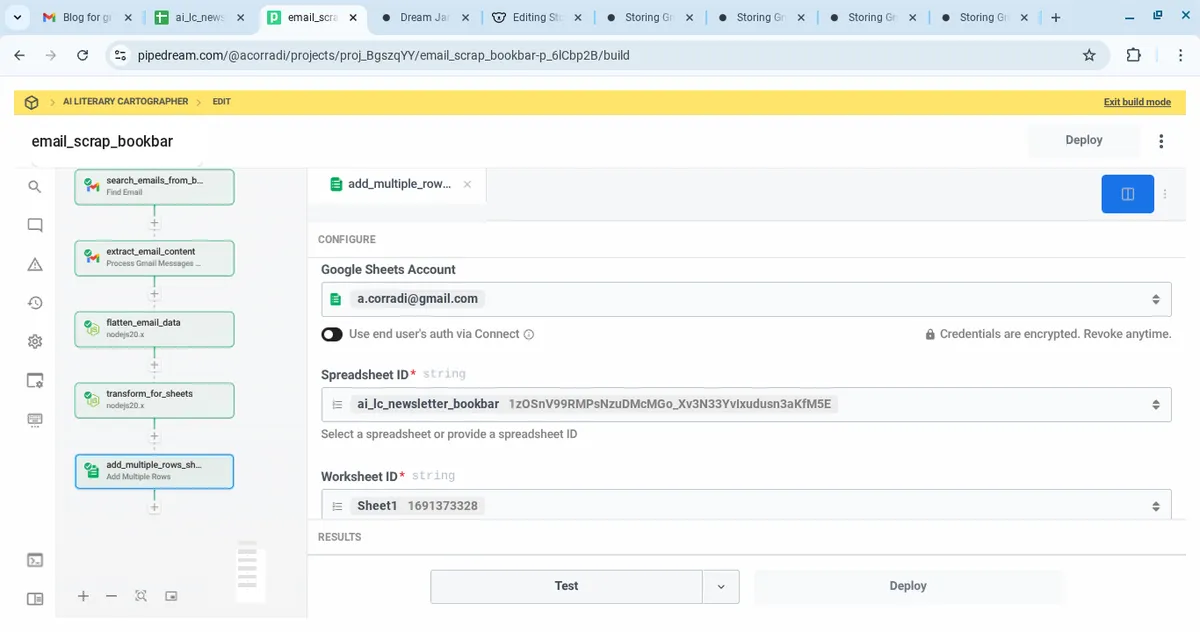
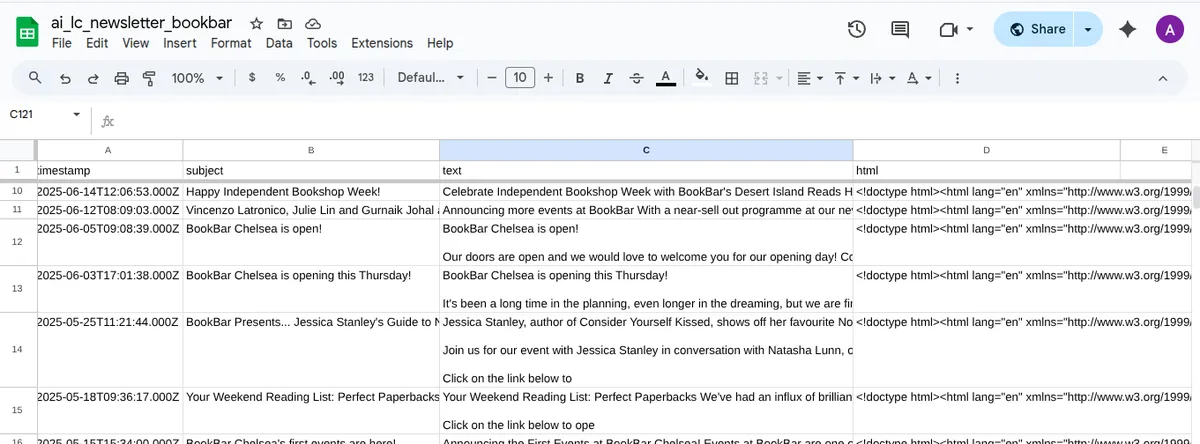
💬 Reflections
This was a surprisingly complex workflow 🥵.
what I learned (the hard way):
- MIME decoding issues were the biggest blockers for sure. Originally I tried to use libraries like
quoted-printableorbase64-arraybuffer, but these caused syntax errors in Pipedream’s Node.js runtime. I ended up using nativeBuffer.from(..., "base64")decoding instead. - Step configuration syntax is important. I kept hitting
expected X to be an arrayerrors due to incorrect return path usage like{{steps.extract_email_content}}instead of{{steps.extract_email_content.$return_value.messages}}. - Visual debugging was critical. Screenshots and raw console logs helped confirm when payloads were successfully decoded.
- Clear separation of logic across steps prevented me from getting overwhelmed (kind of), each Node.js component had a single purpose.
- The final pipeline is now highly reusable and can be cloned and updated for any newsletter source, Daunt Books, Fitzcarraldo etc.
What’s next
- Add support for additional newsletters
- Add a filter to detect and skip duplicate emails
- Feed structured data into the GPT agent (via embeddings or prompt context)